I've been passionate about Test Engineering since learning about the SDET role when interviewing for (then later, preparing for) my first test-focused job at Microsoft. Since then, I've worked as a test lead at Amazon and as a Director of Test or QA at several Atlanta startups, where I've had the privilege of starting and/or maturing several teams.
How did I know if my teams were effective? Absolutely, I kept a close eye on test results, internal defect discovery, and field-found defects. However, effective test organizations do more than catch bugs. They provide organized, meaningful, and timely information about product behavior. They also help inform management about the state of the product.
Aside from bugs and tests, what does a good Test organization look like?
High-functioning Test organizations don't just find bugs - they make the development team more efficient. Test is part of the development workflow. Test activity gives development teams confidence in their teams' output. In high-functioning Test organizations, developers rely on the Test team's output to know that new changes have the desired effect.
Quantitative properties:
- Test failures: annotated, categorized by reason, linked to supporting issues
- Test results: accessible and visible across the organization
- Test cases: visible, discoverable; low false-positive rate; high degree of determinism; run automatically when code changes
Qualitative properties:
- Tests added rapidly in response to new functionality, bugs, inquiries
- Test process facilitates, rather than hinders, development by providing rapid, clear, actionable feedback
Test Organizations - Levels of Sophistication
- Unsophisticated: no automated tests; no testers; test/QA owned by developers
- Low sophistication: dedicated testers check the product for defects before the release
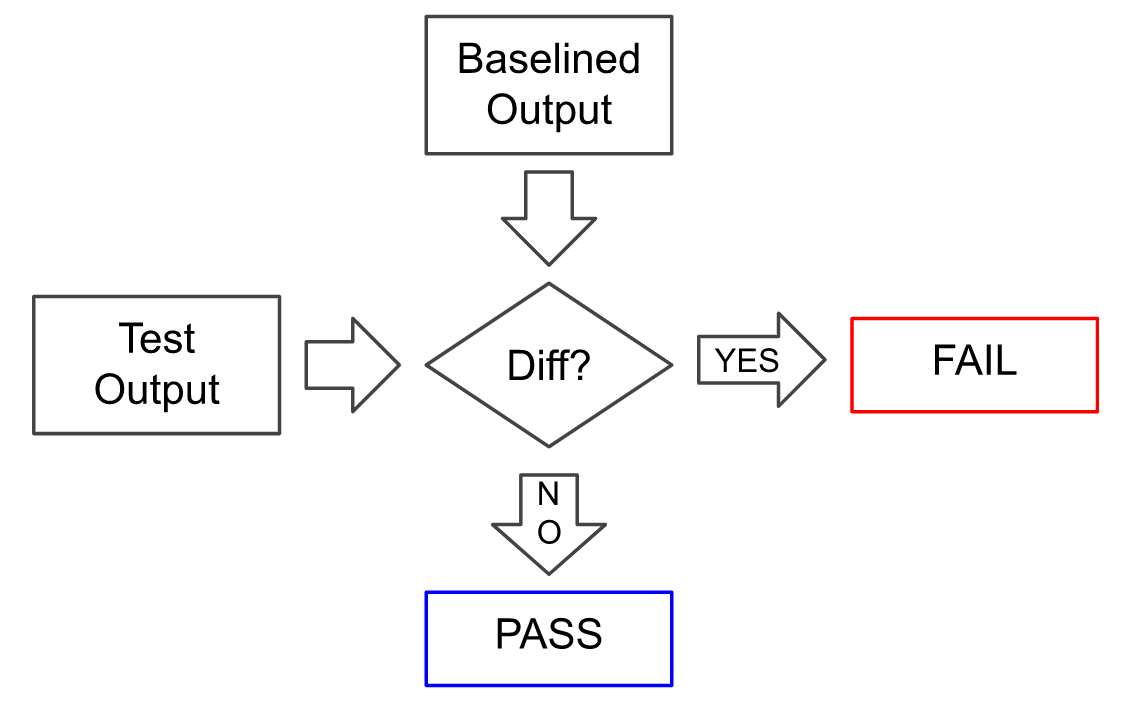
- Moderate sophistication: dedicated testers check products for defects and baseline specifications during the development cycle. Testers provide assistance from automated test suites.
- High sophistication: tests continuously check the product for defects and baseline specifications. Automated tests highlight changes in product behavior as development teams make changes.
In summary, beyond catching bugs, a high-functioning Test organization supports development activities and helps leadership understand the state of the product.